
Authors:
(1) Goran Muric, InferLink Corporation, Los Angeles, (California [email protected]);
(2) Ben Delay, InferLink Corporation, Los Angeles, California ([email protected]);
(3) Steven Minton, InferLink Corporation, Los Angeles, California ([email protected]).
Table of Links
2 Related Work and 2.1 Prompting techniques
3.3 Verbalizing the answers and 3.4 Training a classifier
4 Data and 4.1 Clinical trials
4.2 Catalonia Independence Corpus and 4.3 Climate Detection Corpus
4.4 Medical health advice data and 4.5 The European Court of Human Rights (ECtHR) Data
7.1 Implications for Model Interpretability
7.2 Limitations and Future Work
A Questions used in ICE-T method
3.2 Prompting LLM
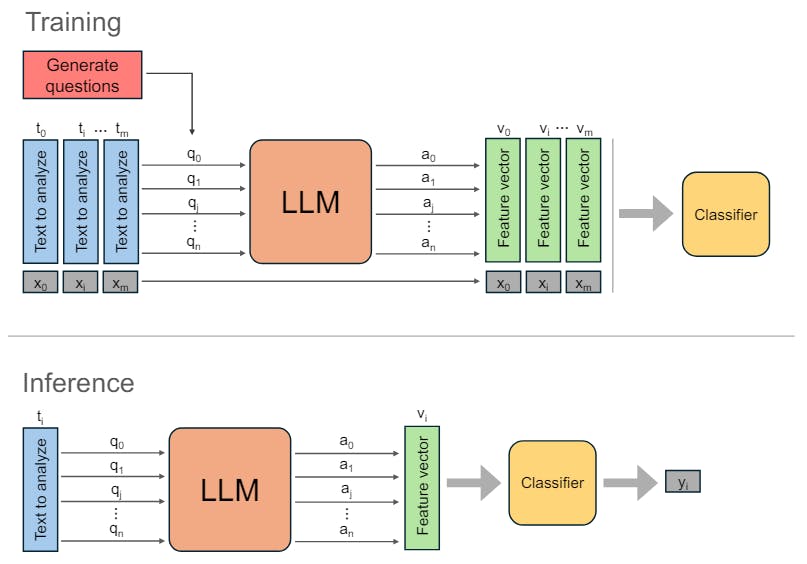
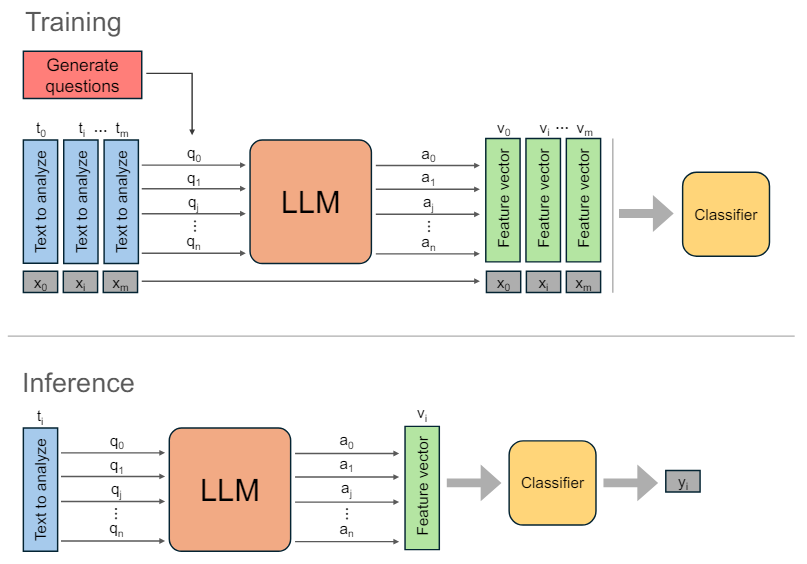
The LLMs are prompted in two occasions. First, they are prompted to obtain the set of secondary questions Q, as described in Section 3.1. Second, for each document, we prompt the LLM with the document and corresponding secondary questions.
Then, for each question qi the output ai of the LLM is collected, creating a set of outputs for each doc-ument. The textual outputs are then assigned a numerical value and transformed into a feature vector vi, through the verbalization process explained in Section 3.3.
3.3 Verbalizing the answers
The output of the LLM in response to each prompt is limited to one of three possible values: Yes, No, or Unknown, depending on the answer to the question posed in the prompt. These responses are subsequently assigned numerical values for analysis, with “Yes” translating to 1, “No” to 0, and “Unknown” to 0.5.
3.4 Training a classifier
To train a classifier, we use a set V of low-dimensional numerical vectors, where |V=n+1 and corresponding labels X, where each vector vi has a corresponding binary label xi. Vectors V are obtained from the training textual data after prompting LLM to generate n + 1 outputs that are then assigned a numerical value. A classifier is then trained using a 5-fold cross-validation process and grid search for the best parameters. A choice of a specific classification algorithm will depend on the size of training data, values distribution and desired performance on a specific classification metric.
This paper is